
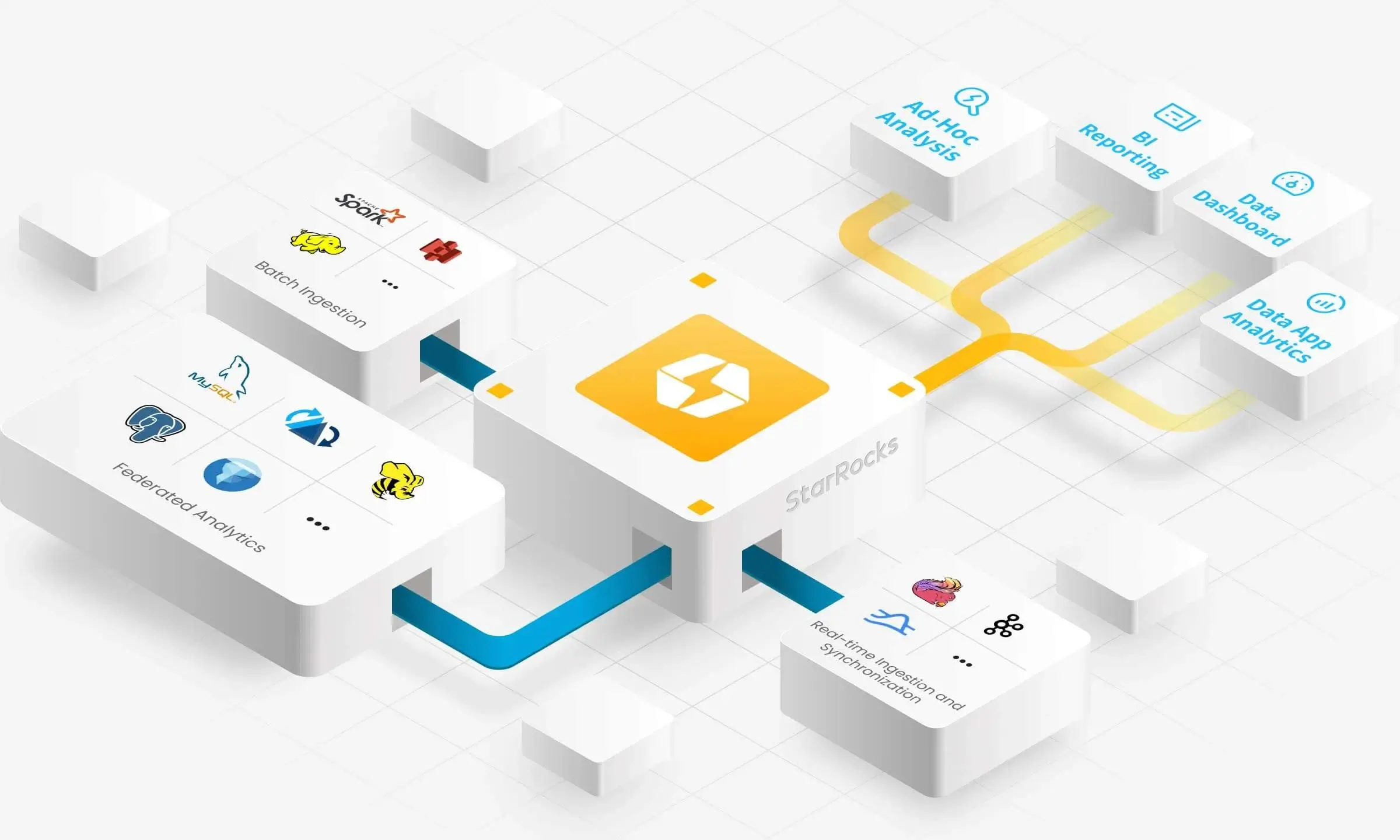
Unlocking the Power of Data and Analytics
StarRocks enables a rapid journey from data to insight.
















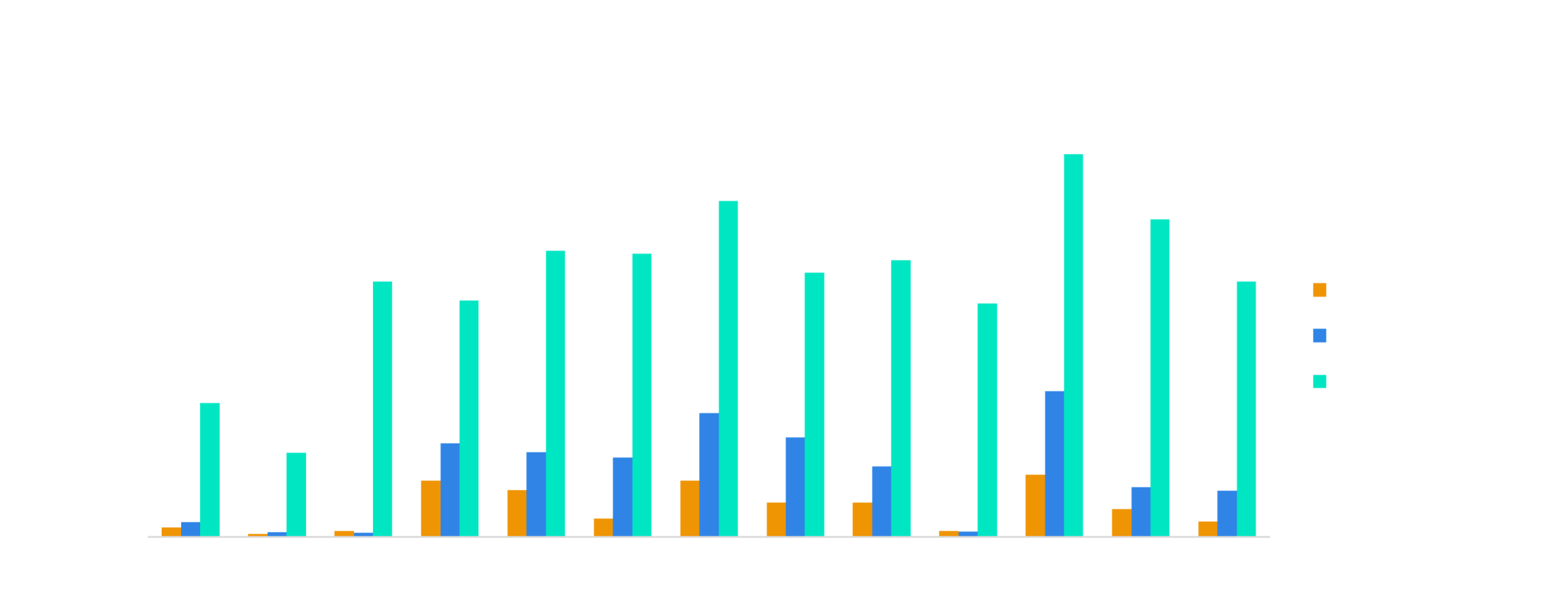
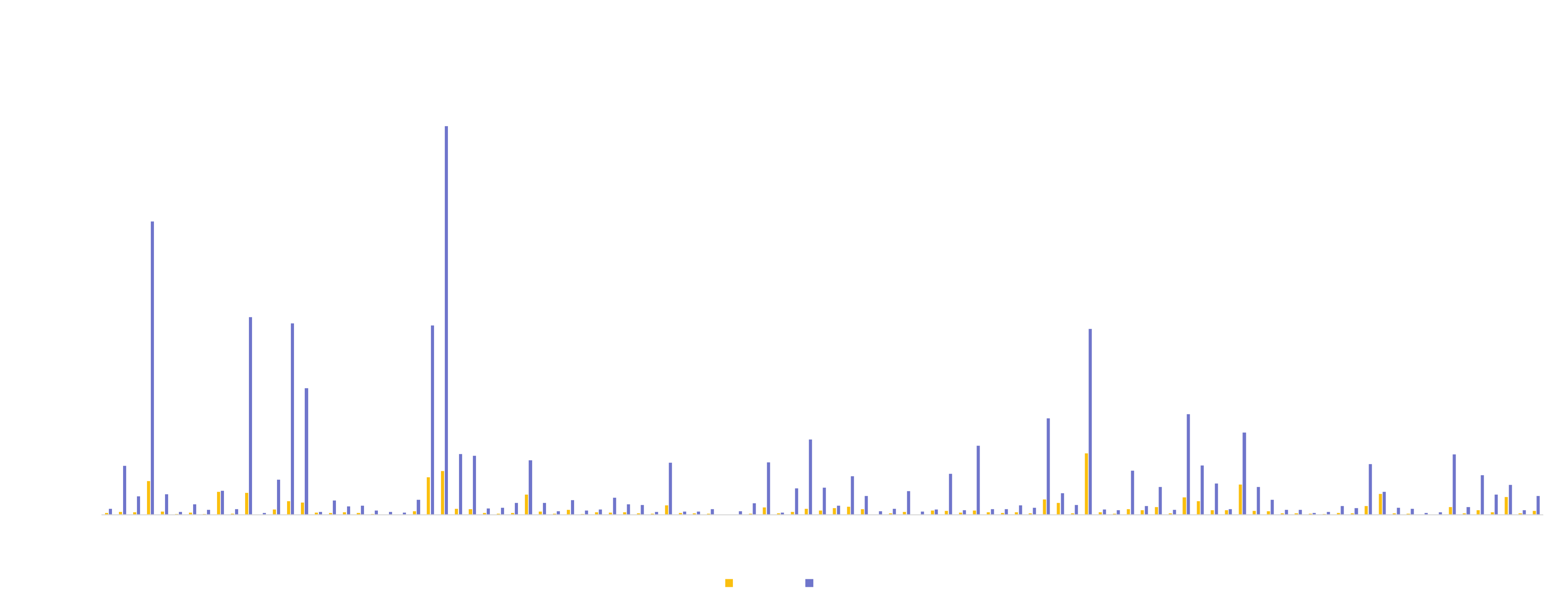
Performance Benchmarks
StarRocks' performance is unmatched, and provides a unified OLAP solution covering the most popular data analytics scenarios.



.png)
Join the StarRocks Slack Community
Share notes, ask questions, and get feedback from thousands of your peers working at world-class companies.
Architecture questions? Answered.
Join 1000+ data engineers, developers and data scientists who share expertise, strategies and best practices.
Product questions?Answered.
Real-life product users and org leaders connect in Slack to get help, give feedback, and highlight new use cases.
New connections? Those too.
Connect with people with similar challenges and the desire to solve them together.
